残差神经网络
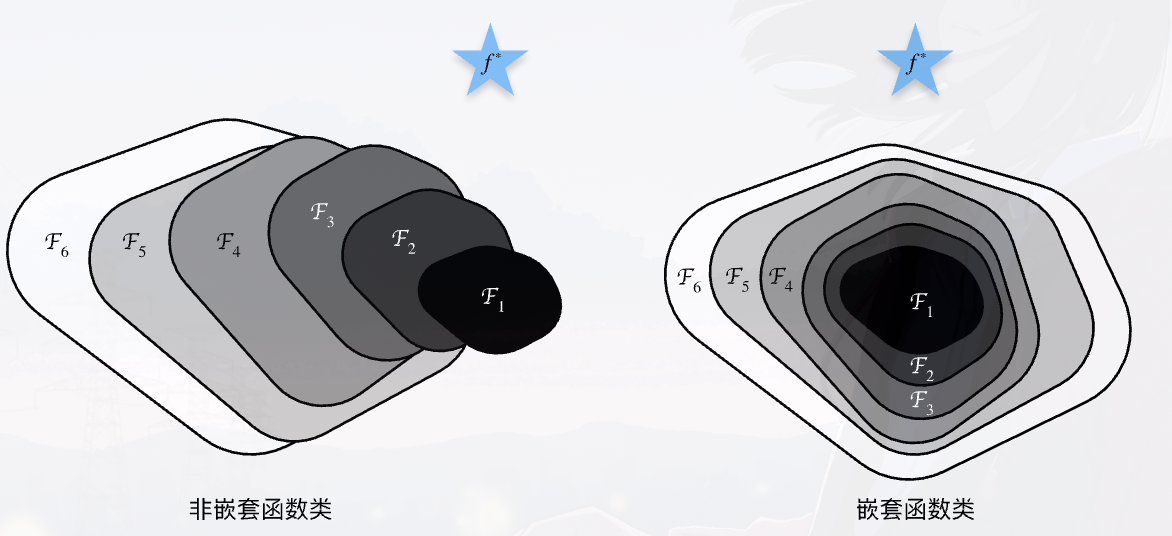
函数类
假设有神经网络架构,考虑其中所有可学习参数的所有情况,假设其能表征的所有函数形成函数类$F$,假设我们最终想要的是函数$f^*$。
- 如果$f^* \in F$,那么我们可以通过训练得到它
- 否则我们往往只能得到一个函数$f^*_{F} \in F$,这是在神经网络架构覆盖的函数类中对于当前数据集表征最好的函数
实际上加深网络的过程,就是为了扩大神经网络对应的函数类的范围
- 但是范围的扩大不意味着更加接近$f^*$
- 我们想确保的是网络的复杂不能导致$F$远离$f^*$(网络衰退),这个时候就需要嵌套函数类,即随着网络复杂程度的增大,所得到的$F_i$是$F_{i+1}$的子集
即我们希望得到下面右图的情况
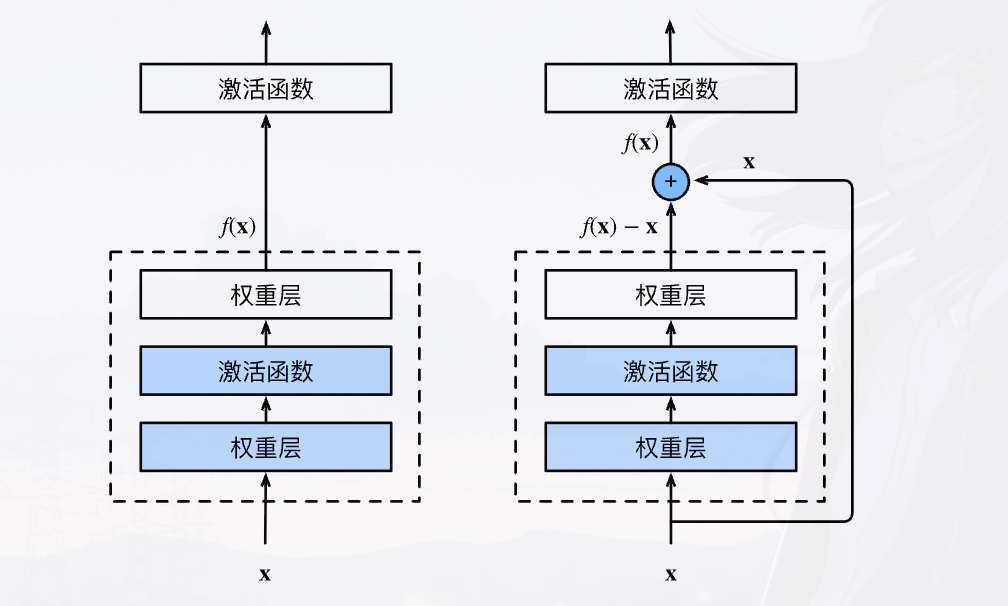
残差块
为了确保随着网络复杂性的增加可以使用残差块
一个正常的前向传播和残差块对比如图
非残差块网络可能得不到嵌套函数类
对于一个普通的非残差网络,第 $L+1$ 层的输出是第 $L$ 层输出 $x_L$ 的非线性变换:
$$x_{L+1} = \mathcal{H}(x_L; W_{L+1}, b_{L+1})$$
通常,$\mathcal{H}$ 是一个带有非线性激活函数(如 ReLU)的仿射变换:
$$x_{L+1} = \sigma(W_{L+1} x_L + b_{L+1})$$
要使普通网络的函数类满足嵌套($\mathcal{F}L \subseteq \mathcal{F}{L+1}$),新增的这一层必须能够精确地表达“恒等映射(Identity Mapping)”,即必须存在一组参数 $W^*$ 和 $b^*$,使得对于所有的 $x_L$,都有:
$$x_{L+1} = \sigma(W^* x_L + b^*) = x_L$$
考虑一种情况:
如果 $\sigma$ 是 ReLU 函数($\max(0, x)$),ReLU 会将所有负数映射为 0。因此,除非 $x_L$ 的所有分量永远是非负的,否则无论你怎么调整权重 $W$ 和偏置 $b$,$\sigma(W x_L + b)$ 都无法完美地等于 $x_L$。
因为新增的层无法完美退化为恒等映射,导致 $\mathcal{F}L \not\subseteq \mathcal{F}{L+1}$。
这就是为什么在 ResNet 提出之前,盲目增加层数会导致“网络退化问题(Degradation Problem)”——更深的网络不仅没有扩大原有的有效搜索空间,反而偏离了浅层网络好不容易找到的优秀解。
残差网络确保嵌套函数类
ResNet 引入了跳跃连接(Skip Connection),改变了网络层的数学表达形式。在残差块中,网络不再直接拟合期望的底层映射 $\mathcal{H}(x)$,而是去拟合残差(Residual) $\mathcal{R}(x)$:
$$x_{L+1} = x_L + \mathcal{R}(x_L; W_{L+1}, b_{L+1})$$
我们同样来检验它是否满足嵌套条件(即 $\mathcal{F}L \subseteq \mathcal{F}{L+1}$)。
为了让 $L+1$ 层的网络等价于 $L$ 层的网络,我们需要:
$$x_{L+1} = x_L$$
代入残差公式,这意味着我们需要:
$$\mathcal{R}(x_L; W_{L+1}, b_{L+1}) = 0$$
数学上的轻易实现:
不管残差块 $\mathcal{R}$ 内部包含多少个 ReLU 和卷积层,只要我们将这一层的权重矩阵 $W_{L+1}$ 全部初始化/优化为零矩阵($\mathbf{0}$),将偏置也设为零,那么:
$$\mathcal{R}(x_L; \mathbf{0}, 0) = \sigma(\mathbf{0} \cdot x_L + 0) = \sigma(0) = 0$$
(对于 ReLU, Tanh 等绝大多数激活函数,输入 0 输出也是 0)。
因此,此时:
$$x_{L+1} = x_L + 0 = x_L$$
结论:
对于残差网络,只需将新增层的参数设为 0,就可以完美实现恒等映射。
在数学上,零映射(Zero Mapping)极其容易通过参数清零来逼近,而恒等映射(Identity Mapping)在非线性网络中却极难逼近。
正因为新增的残差块可以轻而易举地退化为 $0$,所以 $(L+1)$ 层残差网络所能表达的函数集合,严格包含了 $L$ 层网络所能表达的集合。
即:**$\mathcal{F}_1 \subseteq \mathcal{F}_2 \subseteq \dots \subseteq \mathcal{F}L \subseteq \mathcal{F}{L+1}$**
ResNet
ResNet是残差神经网络的典型代表